GSEA富集分析输入文件的准备这一篇文章我们就要向大家讲解GSEA富集分析了,在做GSEA富集分析之前,我们要准备好输入文件,我们要准备如下信息: 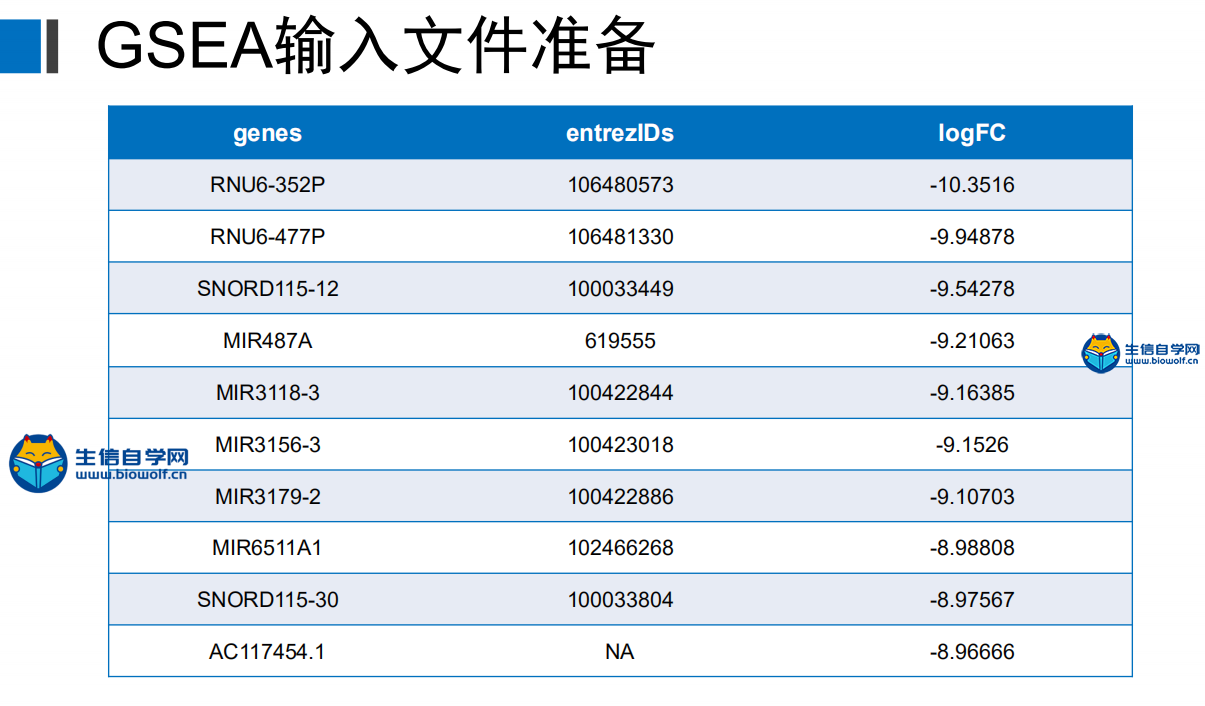 第一列为基因名称,第二列为基因的id,第三列是基因的logFC,这个文件按照了logFC进行了排序 要得到这样的输入文件,我们要用到基因的表达量文件,用来求基因的logFC,这个文件就是我们很早以前得到的symbol.txt文件,还需要一个病人的风险分组的文件,从里面我们可以知道病人的风险是高风险还是低风险,同样也是 用来就logFC值。 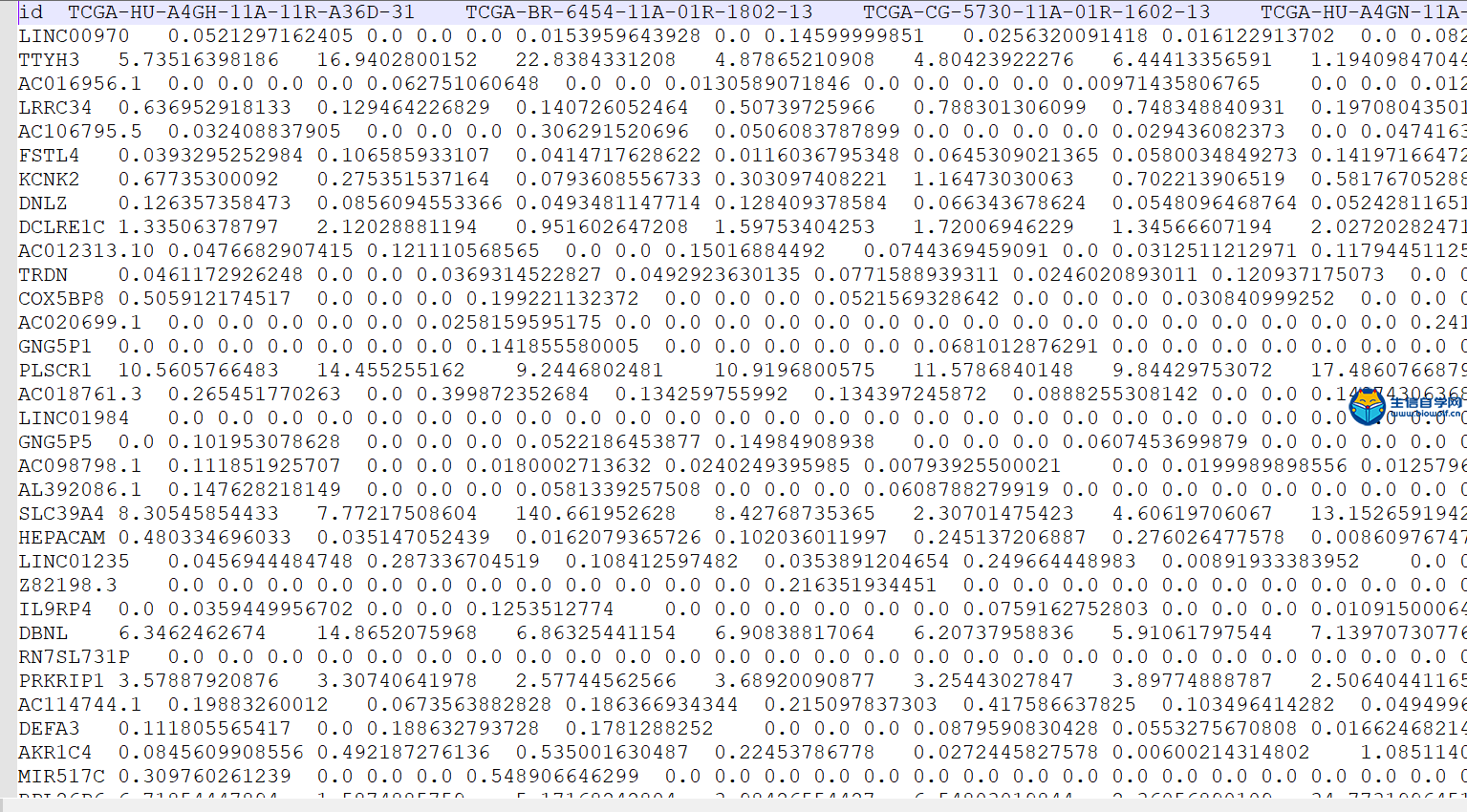 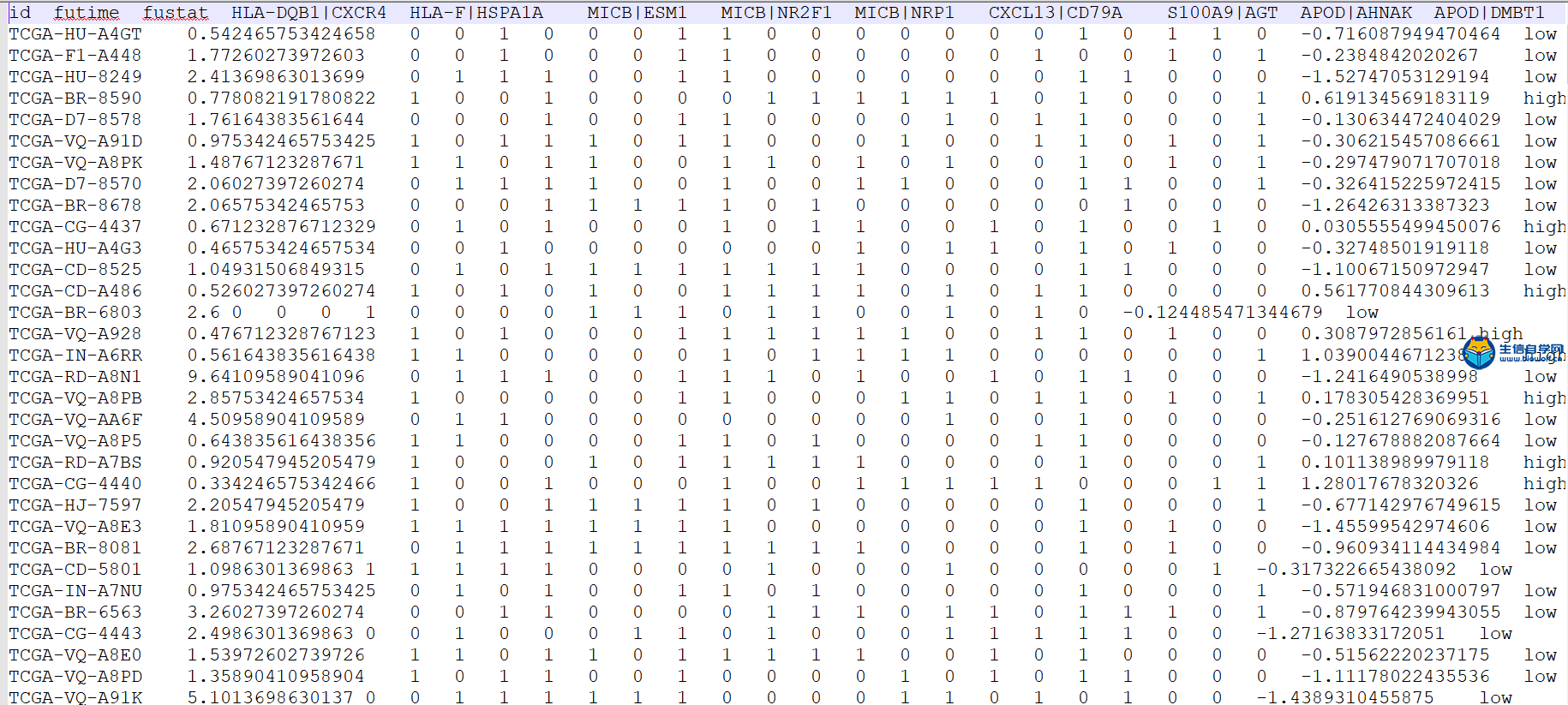 通过运行我们事先写好的脚本,我们会得到一个id.txt文件,这个文件就是我们做GSEA富集分析所需要的输入文件  GSEA富集分析 得到输入文件后,我们就可以做GSEA的富集分析,在通过GSEA的富集分析,我们可以得到这样的一个表格 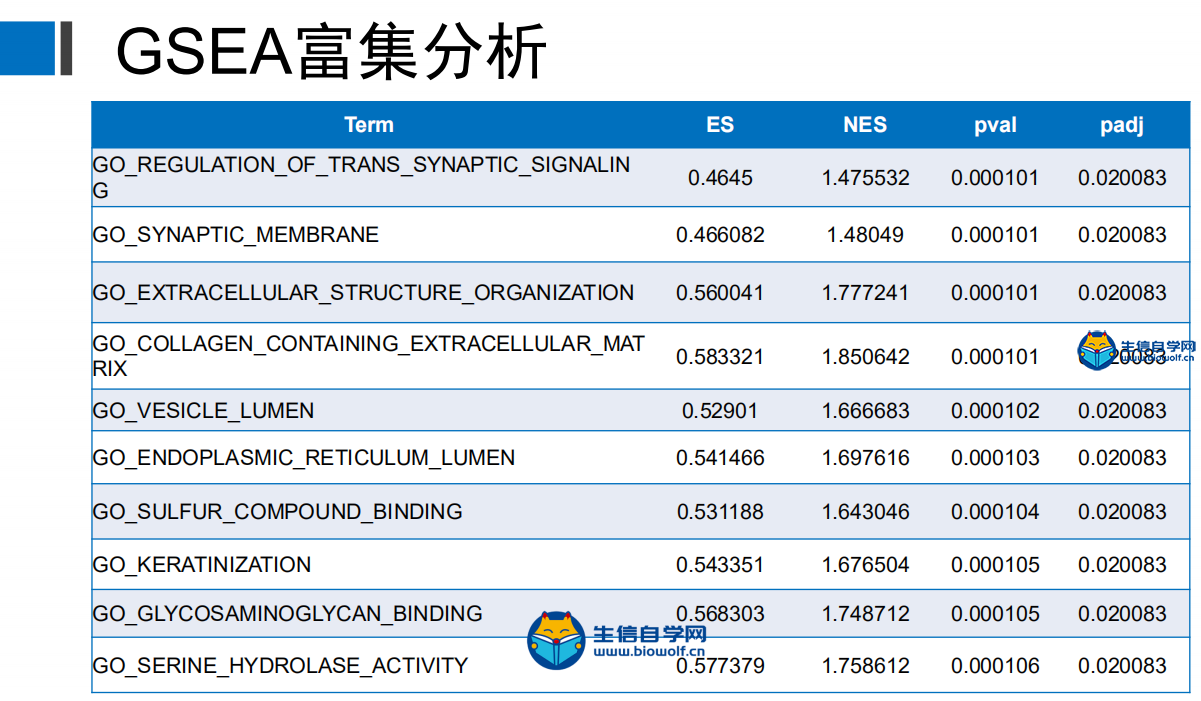 从这个表格我们可以得到GO的名称(第一列),富集的打分(第二列),矫正后的打分(第三列),然后是富集的显著性和矫正后的P值。这就是我们可以得到的5列信息,我们在矫正的时候一般是按矫正后的P值小于0.05进行筛选,得到富集显著的一些功能或者通路。 得到这表格后我们还可以对GSEA富集的结果进行可视化得到如下的富集图 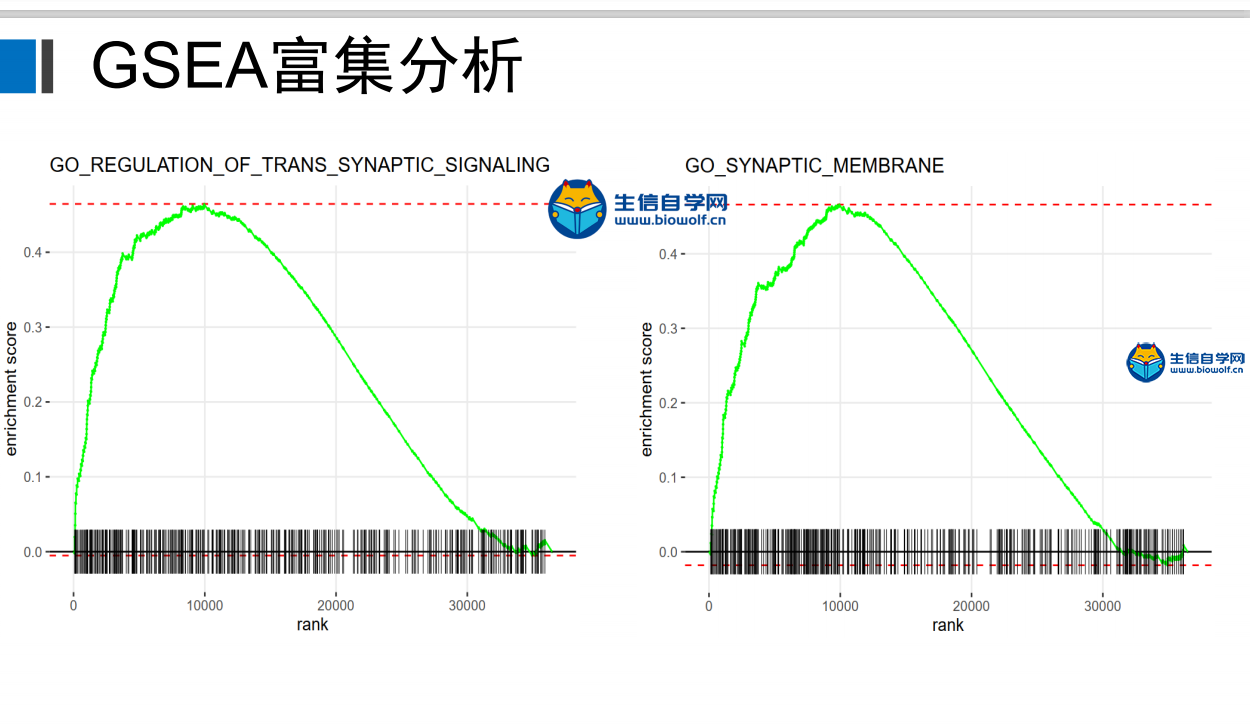 这个图形上方是GO的名称,横坐标代表我们排序好的基因,这里面竖线比较密集的地方代表这里的基因存在与对应的GO里面,所以打分就比较高,这个最高的打分就是我们最终富集的打分。 要做GSEA的富集分析,除了准备基因的文件,我们还要准备基因集文件,这个文件我们要从GSEA的官网下载,下载过程我们会在下一篇文章中向大家单独讲解,感兴趣的话可以关注我们的公众号或者直接通过下方的链接购买我们视频 下载好了文件以后,只需要用R运行我们提供的脚本文件,我们就会得到很多个图形文件和一个txt文件,这个就是我们富集分析的结果文件。  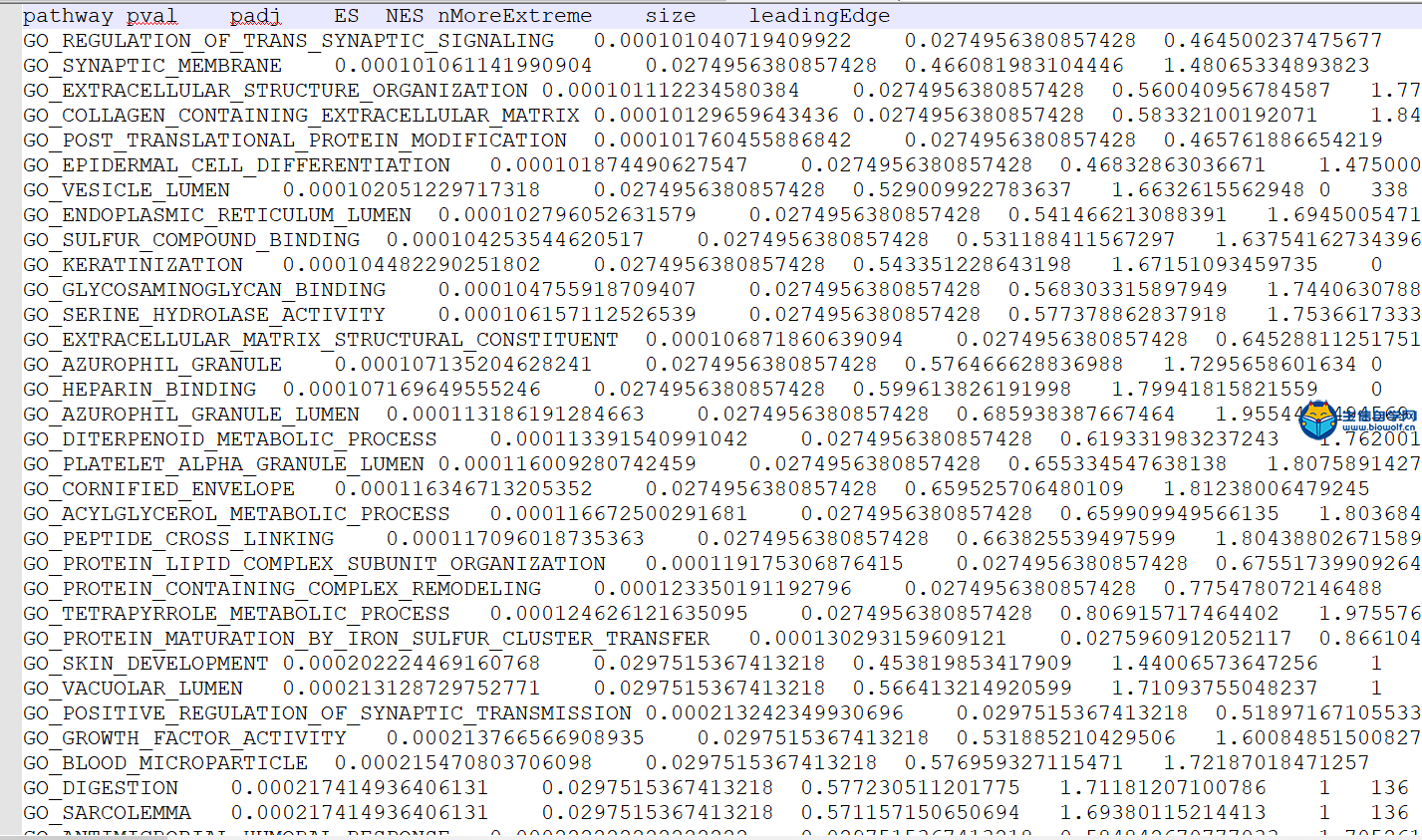 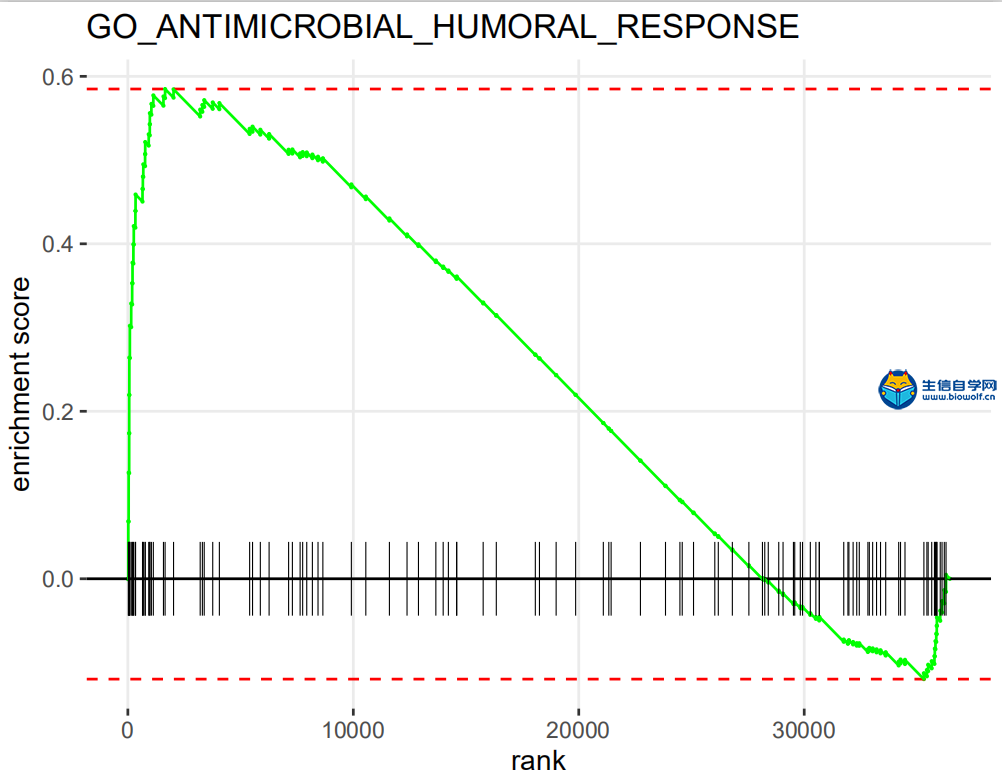 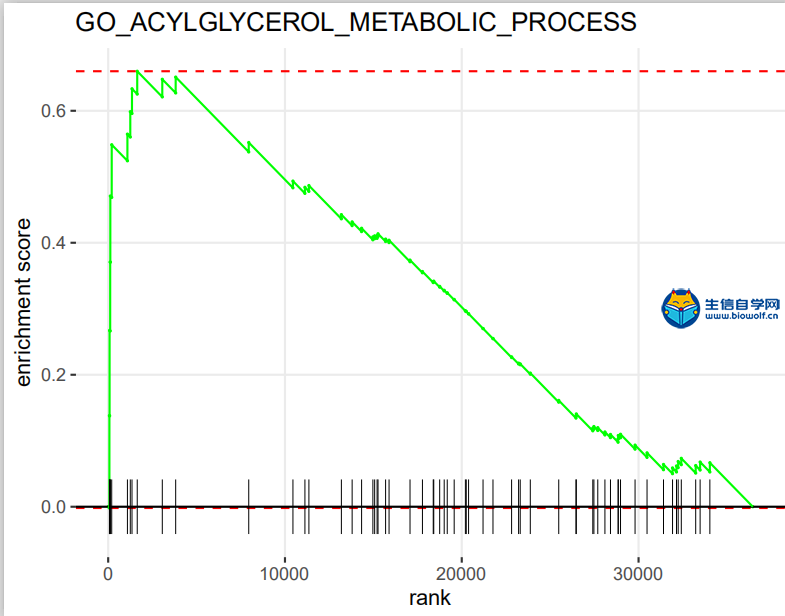 视频购买链接: 《免疫基因对文章套路视频》 精品课程推荐: 《GEO数据库miRNA芯片挖掘》 《甲基化肿瘤分型文章套路视频》 《TCGA肿瘤免疫细胞浸润模式挖掘》 
责任编辑:伏泽 作者申明:本文版权属于生信自学网(微信号:18520221056)未经授权,一律禁止转载! |




